Fine-tuning a CLOOB-Conditioned Latent Diffusion Model on WikiArt

Prompt: ‘A sunset landscape painting, oil on canvas’ (fine-tuned Wikiart model)
As part of the Huggingface ‘#huggan’ event, I thought it would be interesting to fine-tune a latent diffusion model on the WikiArt dataset, which (as the name suggests) consists of paintings in various genres and styles.
What is CLOOB-Conditioned Latent Diffusion?
Diffusion models are getting a lot of fame at the moment thanks to GLIDE and DALL-E 2 which have recently rocked the internet with their astounding text-to-image capabilities. They are trained by gradually adding noise to an input image over a series of steps, and having the network predict how to ‘undo’ this process. If we start from pure noise and have the network progressively try to ‘fix’ the image we eventually end up with a nice looking output (if all is working well).
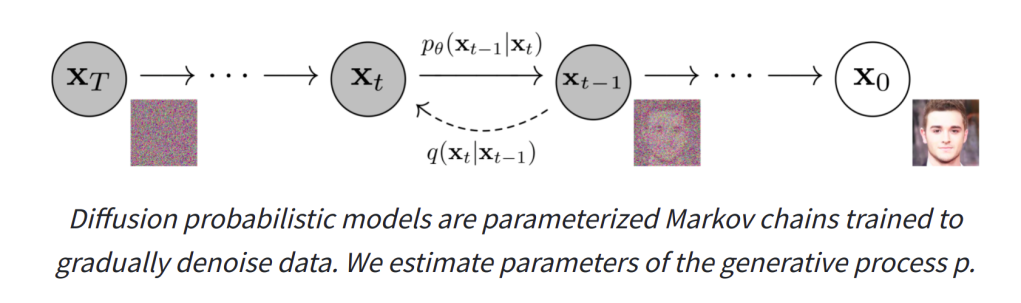
An illustration of this kind of model from the website related to one of the key papers that first outlined this idea.
To add text-to-image capacity to these models, they are often ‘conditioned’ on some representation of the captions that go along with the images. That is, in addition to seeing a noisy image, they also get an encoding of the text describing the image to help in the de-noising step. Starting from noise again but this time giving a description of the desired output image as the text conditioning ideally steers the network towards generating an image that matches the description.
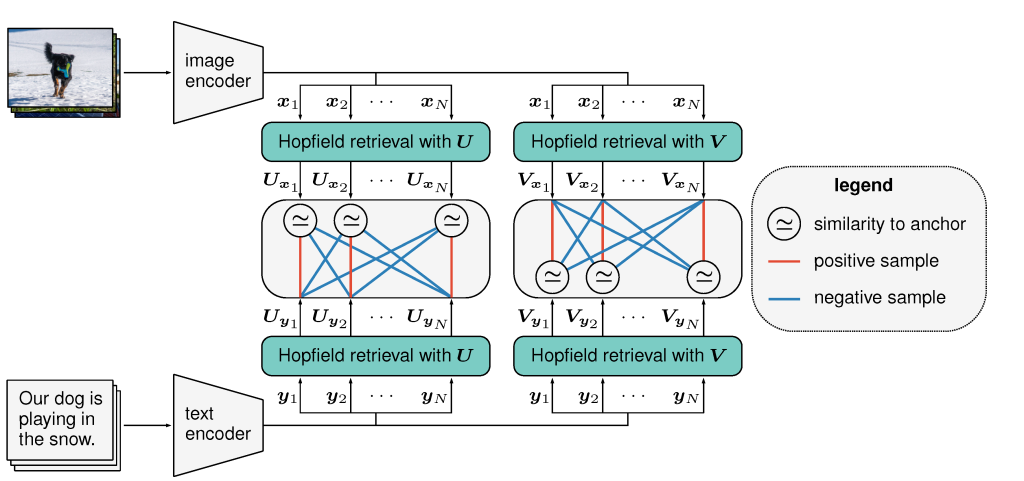
CLOOB architecture diagram (from the project page - which is worth a read!)
Downsides: these diffusion models are computationally intensive to train, and require images with text labels. Latent diffusion models reduce the computational requirements by doing the denoising in the latent space of an autoencoder rather than on images directly. And since CLOOB maps both images and text to the same space, we can substitute the CLOOB encodings of the image itself in place of actual caption encodings if we want to train with unlabelled images. A neat trick if you ask me!
The best non-closed text-to-image implementation at the moment is probably the latent diffusion model trained by the CompVis team, which you can try out here.
Training/Fine-Tuning a model
@JDP provides training code for CLOOB conditioned latent diffusion (https://github.com/JD-P/cloob-latent-diffusion) based on the similar CLIP conditioned diffusion trained by Katherine Crowson (https://github.com/crowsonkb/v-diffusion-pytorch). One of my #huggan team members, Théo Gigant, uploaded the WikiArt dataset to the huggingface hub, and the images were downloaded, resized and saved to a directory on a 2xA6000 GPU machine provided by Paperspace.
After a few false starts figuring out model loading and other little quirks, we did a ~12 hour training run and logged the results using Weights and Biases. You can view demo outputs from the model as it trains in the report, which thanks to the W&B magic showed them live as the model was training, making for exciting viewing among our team :)
Evaluating The Resulting Model
WikiArt is not a huge dataset relative to the model (which has over a billion parameters). One of the main things we were curious about was how the resulting model would be different from the one we started with, which was trained on a much larger and more diverse set of images. Has it ‘overfit’ to the point of being unuseable? How much more ‘arty’ do the results look when passing descriptions that don’t necessarily suggest fine art? And has fine-tuning on a relatively ‘clean’ dataset lowered the ability of the model to produce disturbing outputs? To answer these questions, we generated hundreds of images with both models.



Generated images from the prompts ‘winter landscape’, ‘autumn landscape’ and ‘spring landscape’ (WikiArt model). Note: all results are ‘painterly’ despite no allusion to paintings or art in the prompts. Seeds kept consistent for each set - note the slight similarity in overall structure for corresponding images.
I’ve moved the side-by-side comparisons to a gallery at the end of this post. These were the key takeaways for me:
- Starting from a ‘photorealistic’ autoencoder didn’t stop it from making very painterly outputs. This was useful - we thought we might have to train our own autoencoder first as well.
- The type of output definitely shifted, almost everything it makes looks like a painting
- It lost a lot of more general concepts but does really well with styles/artists/image types present in the dataset. So landscape paintings are great, but ‘a frog’ is not going to give anything recognizable and ‘an avocado armchair’ is a complete fail :)
- It may have over-fit, and this seems to have made it much less likely to generate disturbing content (at the expense of also being bad at a lot of other content types).
Closing Thoughts
Approaches like CLOOB-Conditioned Latent Diffusion are bringing down the barrier to entry and making it possible for individuals or small organisations to have a crack at training diffusion models without $$$ of compute.

Our model during training (left) vs OpenAI’s DALL-E 2 (right) which was unveiled during our project and inspired various memes :)
This little experiment of ours has shown that it is possible to train one of these models on a relatively small dataset and end up with something that can create pleasing outputs, even if it can’t quite manage an avocado armchair. And as a bonus, it’s domain-focused enough that I’m happily sharing a live demo that anyone can play with online, without worrying that it’ll be used to generate any highly-realistic fake photographs of celebrity nudity or other such nonsense. What a time to be alive!
Comparison images

A watercolor painting of a rose

Autumn watercolor

Autumn landscape

A Monet Pond

A pink lilly

Tarsila do Amaral

Blue and pink hydrangeas, impressionistic oils

New York skyline in winter

A face, portrait in oils
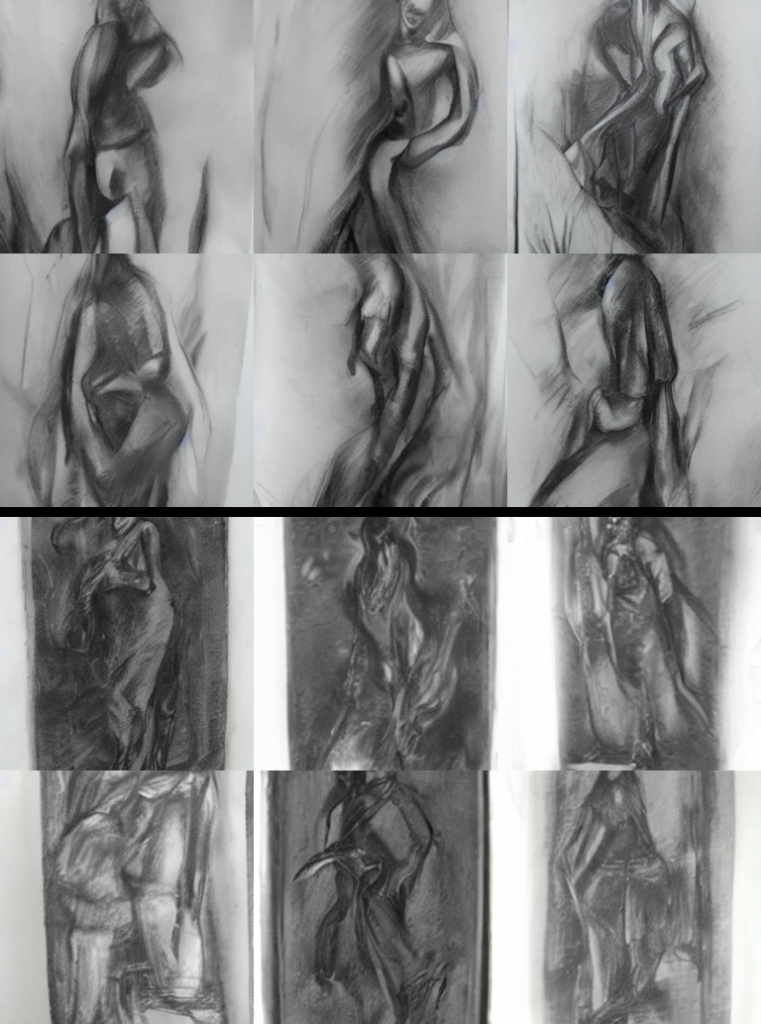
A female figure, charcoal

The moon over a landscape

Peaceful Blue
Comparison images from our finetuned model (top) and the original model (bottom). Captions are the prompts used.